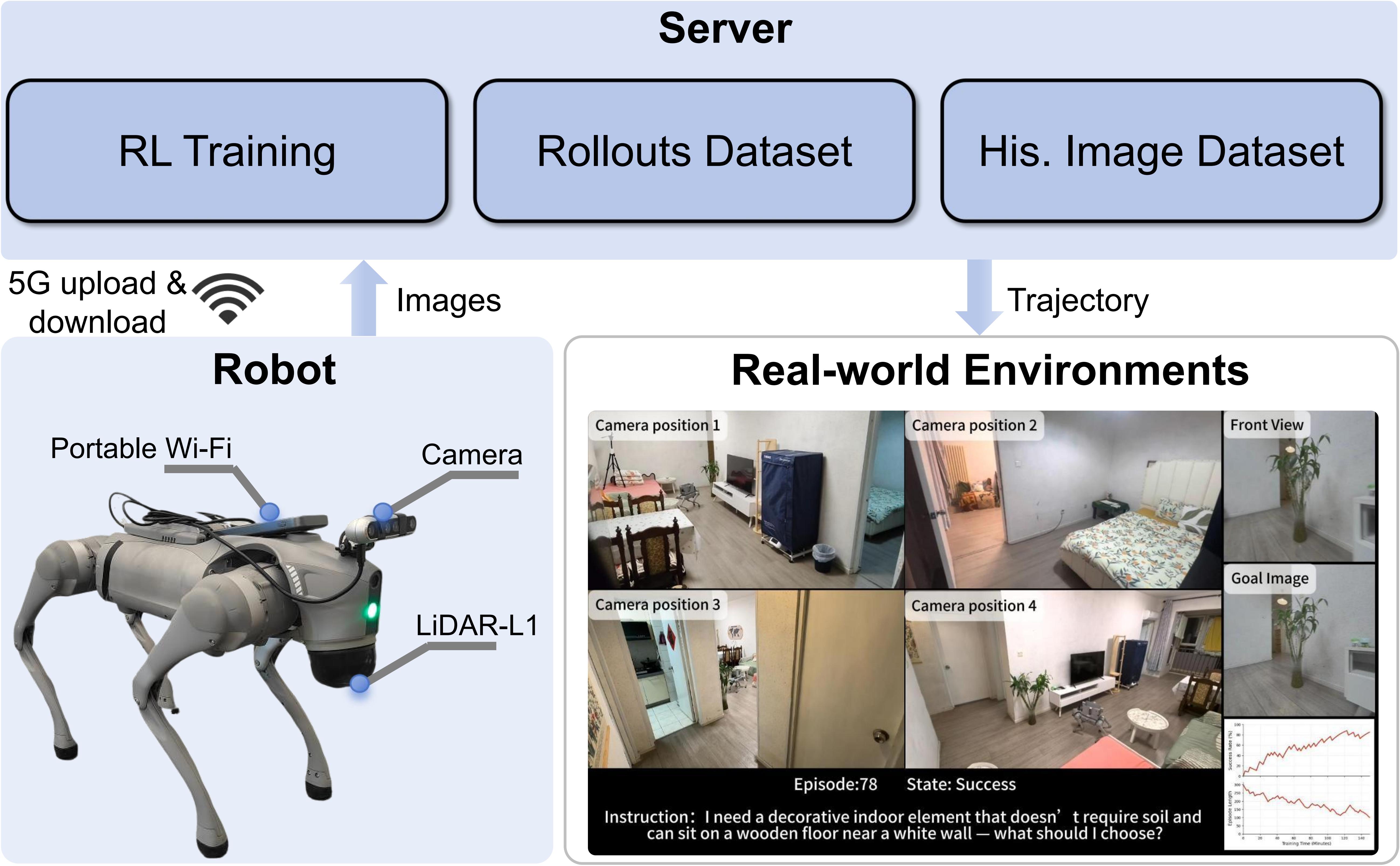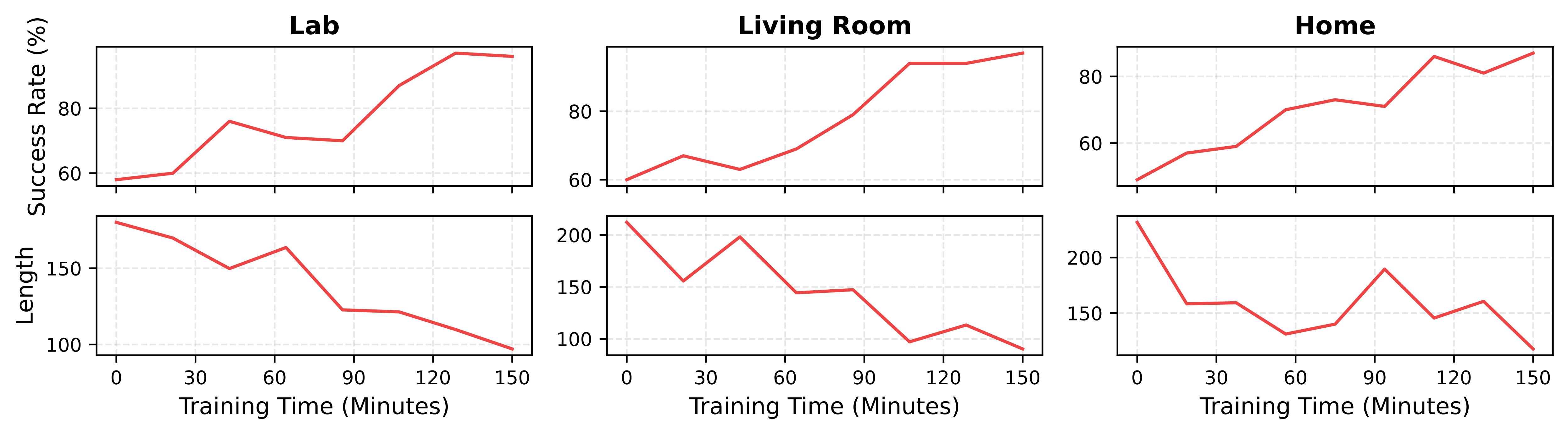
AllDayNav achieves near-100% success rates in lifelong navigation through memory-driven reinforcement learning. The robot autonomously builds a self-evolving multimodal memory, generates self-instructions, and continuously improves its navigation policy without human supervision.